In the rapidly evolving field of next-generation sequencing (NGS) and precision medicine, data sovereignty has emerged as a critical concern for bioinformatic operations. Healthcare organizations, molecular diagnostic laboratories, and government-funded genome centers worldwide increasingly recognize that maintaining complete control over high-dimensional genomic data isn’t merely about regulatory compliance—it’s fundamentally about scientific autonomy, institutional independence, and long-term data stewardship within a secure infrastructure paradigm.
At Golden Helix, our bioinformatics platform has consistently championed a data-control-first approach, architecting our technical framework around empowering customers to own their valuable genomic assets. Your genomic data assets should remain within your organization’s security perimeter and access control framework.
The Increasing Importance of Data Sovereignty in Genomic Analysis
The genomic revolution, accelerated by dramatic reductions in sequencing costs from ~$3B per genome in 2001 to under $100 today, generates large data repositories requiring sophisticated stewardship. A typical whole genome sequence (WGS) generates approximately 100-150 gigabytes of raw data per sample, while targeted panels and exomes produce 1-10 gigabytes each. These datasets rapidly expand at scale into the petabyte range, with significant computational requirements for variant calling, annotation, and interpretation.
Organizations investing in genomic medicine infrastructure are finding that maintaining control over these datasets is essential for several technically driven reasons:
- Enhanced bioinformatic security protocols tailored to specific institutional requirements, including granular access controls for researchers, clinicians, and computational biologists
- Long-term data accessibility and pipeline reproducibility regardless of vendor changes or market consolidation, ensuring clinical and research continuity
- Algorithmic independence from third-party proprietary bioinformatic implementations
- Compliance with evolving regulatory frameworks, including HIPAA, GDPR, IVDR, CLIA, CAP, and jurisdictional genetic privacy laws, is also country-specific.
These technical considerations have driven many of our research and clinical customers to prioritize solutions that maintain their genomic data firmly within their own computational infrastructure and governance frameworks.
On-Premises Solutions: The Gold Standard for Security-Critical Genomic Environments
For many of our customers, particularly government genome centers, clinical testing laboratories, and healthcare organizations with strict data governance requirements, on-premises deployment architecture remains the preferred technical approach. These organizations leverage our software stack for its ability to provide:
- Hardened computational security protocols that integrate with existing infrastructure security management systems
- Alignment with institutional data governance policies, including role-based access controls (RBAC) for variant databases
- Seamless integration with existing high-performance computing (HPC) environments for computationally intensive processes like alignment, variant calling, and annotation
- Completely air-gapped bioinformatic environments with zero external network dependencies, creating physical isolation that prevents exfiltration vectors
On-premises genomic analysis solutions provide the highest control over sensitive genetic data, maintaining Protected Health Information (PHI) within organizational boundaries. While these implementations require dedicated computational resources for processing NGS data through resource-intensive pipelines (BWA-MEM alignments, variant calling, etc.), healthcare institutions performing genetic testing often find this investment scientifically and operationally justified, given the sensitivity of germline and somatic mutation information.
Customer-Controlled Cloud Infrastructure: Computational Elasticity Without Compromising Data Governance
While on-premises deployment offers the highest level of security control, we recognize that many organizations are shifting toward cloud infrastructure to improve computational elasticity and reduce bioinformatic infrastructure management overhead. Genomic analysis workflows often exhibit variable computational demands, with periodic intensive processing requirements during batch sequencing runs followed by lower utilization periods. In response to these workload patterns, we’ve engineered deployment options for AWS and Azure — including private cloud genomics configurations — that maintain the critical principle of customer data control while enabling elastic compute resource utilization.
Unlike most bioinformatic competitors in the genomic analysis space, our cloud implementations deploy within the customer’s Virtual Private Cloud (VPC). This architecture ensures:
- Your organization maintains complete ownership of the cloud infrastructure stack and encryption keys
- Genomic data remains within your security perimeter, avoiding multi-tenant data storage models
- You retain granular control over Identity and Access Management (IAM) permissions and authentication systems
- Your IT security team retains complete visibility into all system operations via CloudTrail/Azure Monitor logs
- Data residency requirements can be satisfied by selecting appropriate regional deployments
This approach delivers the computational elasticity benefits of cloud computing with containerized bioinformatic pipelines (Docker/Kubernetes orchestration) without surrendering control of sensitive genetic information to third parties. Customers can choose to implement this model with FISMA Moderate or FedRAMP-compliant configurations to meet enhanced security requirements.
The Multi-Tenant Architecture Vulnerability: Technical and Scientific Considerations
Most genomic analysis providers require customers to upload their sequencing data to multi-tenant cloud environments controlled by the vendor. This architectural approach creates several significant technical vulnerabilities and scientific concerns that organizations should carefully evaluate:
1. Inherent Security and Isolation Limitations
Multi-tenant environments necessarily involve shared computational and storage infrastructure components. Despite logical separation between customer datasets via containerization or virtualization, these environments introduce additional attack vectors compared to dedicated infrastructure. Recent cybersecurity research has highlighted several technical risks specific to multi-tenant cloud architectures housing genomic data:
- Tenant isolation vulnerabilities that could potentially allow data exfiltration between tenants through side-channel attacks targeting shared memory subsystems
- Hypervisor vulnerabilities are security issues affecting the virtualization layer, which could compromise multiple customer environments
- Increased attack surface due to the complexity of managing multiple tenant environments with diverse genomic datasets
- Limited encryption control that often keeps encryption key management within the vendor’s security domain rather than the data owner’s
2. Business Continuity and Data Persistence Risks
The recent 23andMe bankruptcy filing provides a sobering scientific and ethical case study of what happens when sensitive genomic data (containing SNPs, CNVs, and other genetic variants) is entrusted to third-party platforms. When organizations upload sequencing data to vendor-controlled platforms, they become vulnerable to the vendor’s business fortunes with limited technical recourse.
The 23andMe situation has raised significant concerns about genomic data ownership, persistence, and access rights in the scientific and regulatory communities. As documented in numerous legal actions, state officials, including the attorneys general in California and New York, have advised customers to delete their genetic data promptly. At the same time, they still maintain access rights, a clear demonstration of the scientific, legal, and operational vulnerabilities created when an organization relinquishes control of genetic information to a third party. From a research continuity perspective, this scenario illustrates the fragility of third-party data repositories that may contain irreplaceable cohort data.
3. Competitive Intelligence Exposure and Intellectual Property Vulnerabilities
Bioinformatics industry consolidation creates additional data governance risks with scientific and intellectual property implications. The recent acquisition of Fabric Genomics by GeneDx (announced in April 2025) illustrates this point from a technical perspective. When Fabric Genomics was acquired, their customers—many of whom operate competing genomic testing laboratories—suddenly found themselves with their proprietary genetic variant datasets and testing algorithms housed within computational infrastructure controlled by GeneDx, a direct competitor in the clinical genomic testing space. This scenario creates significant scientific and intellectual property concerns regarding potential competitive intelligence derivation that don’t exist when organizations maintain full infrastructure control over their genomic data assets. Clinical laboratories invest substantially in developing proprietary variant classification schemes, phenotype-genotype correlations, and interpretation algorithms representing valuable intellectual property. When these assets are hosted on your infrastructure, whether on-premises or in your controlled cloud environment with end-to-end encryption, you maintain technical isolation from potential competitive exposure during industry consolidation events.
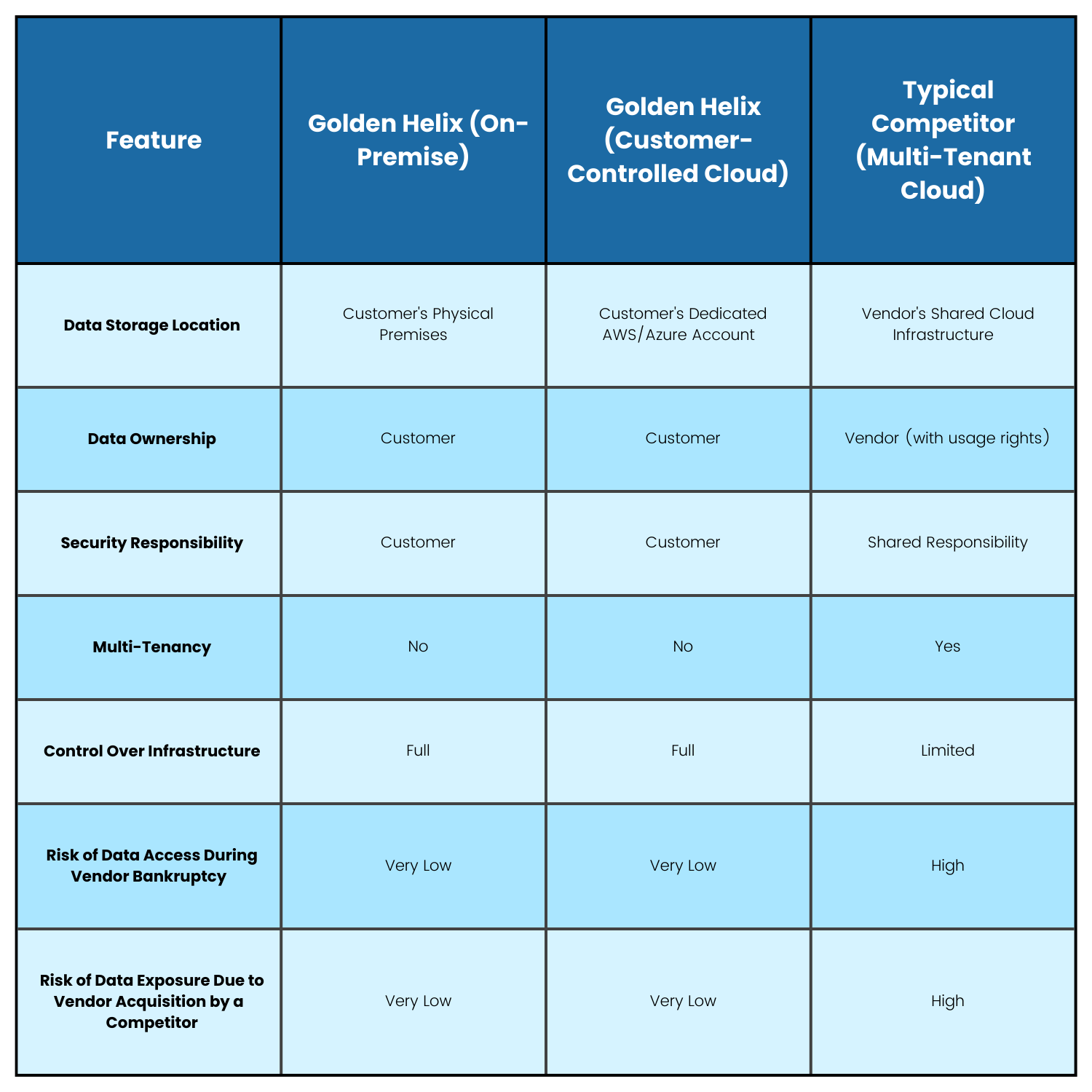
Implementing a Scientifically Sound Data Governance Strategy
As organizations evaluate their NGS analysis software and bioinformatic infrastructure options, we encourage you to consider your data architecture strategy’s long-term scientific, operational, and security implications. While multi-tenant SaaS offerings may initially offer computational convenience, they frequently introduce hidden technical costs regarding reduced data control, potential security vulnerabilities in shared environments, and exposure to vendor business risks that can jeopardize research continuity.
We remain committed to providing bioinformatic solutions that empower our customers to fully control their valuable genomic data assets while benefiting from our advanced variant analysis capabilities. Whether through on-premises deployment or customer-controlled cloud infrastructure, our technical approach ensures that your organization maintains the data sovereignty it needs over its critical genomic resources.
The precision medicine revolution, driven by next-generation sequencing technologies and sophisticated genomic analysis, promises to transform healthcare delivery through personalized therapeutic approaches based on patients’ molecular profiles. However, realizing this scientific potential requires careful attention to the technical aspects of genomic data governance, persistence, and security. By implementing infrastructure that maintains complete organizational control over sensitive genetic information throughout its lifecycle—from FASTQ files through BAM alignment, VCF variant calling, and final clinical interpretation—you establish a sustainable foundation for long-term scientific progress while protecting your most valuable bioinformatic assets and intellectual property.



