Creating and managing sample manifest files in VarSeq has traditionally been a time-consuming process that demands precision and attention to detail. The upcoming VSWarehouse 3 release will feature the ability to use catalogs to save and load sample fields in VarSeq projects. Not only will this allow for easy population of sample fields in VarSeq, but it also has the potential to enable longitudinal tracking of samples as they are added. In this article, we will briefly touch on how catalogs can be used to import sample fields, as well as how they can be used to save sample values created by VarSeq algorithms.
Importing Sample Fields from Catalogs
Samples can be added to the sample catalogs during secondary analysis with a set of public APIs, or fields can be added manually on the server at the same time that the sample sheet is created for the sequencer run. When this is done ahead of time, the fields can be added by selecting the “From Catalog” button in the Import Variants Wizard.
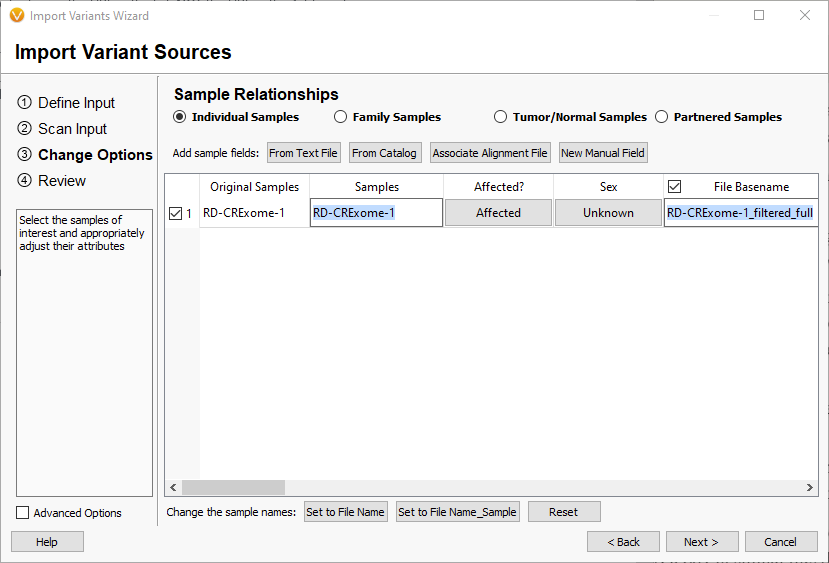
This will open the catalog selection dialog, which allows you to pick the catalog with the fields you want to add before importing it into VarSeq.
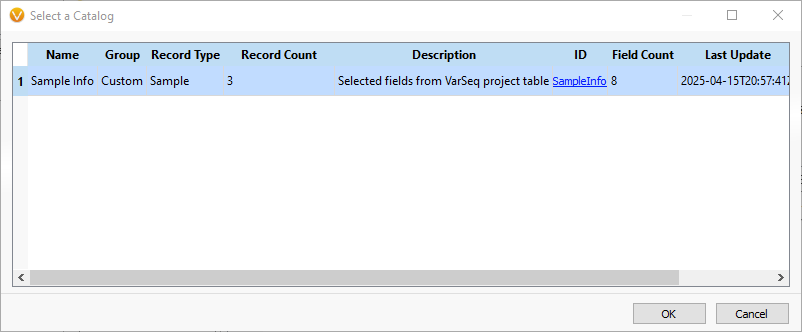
Click “OK” to select the catalog, and the fields from that catalog will be automatically added to the sample table. The fields will be filled with the values from the matching Sample ID in the table. This allows any number of fields to be added, including:
- Gene Lists
- BAM Paths
- Gene Panels
- Sample Sex
- Sample Affection Status
- Pedigree information
With these fields added on import, downstream algorithms like Compound Het, Match Gene List (Per Sample), and CNV analysis can run automatically. The catalog ID can also be specified on the command line to allow automated import of sample fields for your VSW3 VSPipeline workflows.
Uploading Sample Data
Sample data can be added to the catalog in many different ways. The first and maybe the most obvious is through the catalog editor in VSWarehouse or in VarSeq:
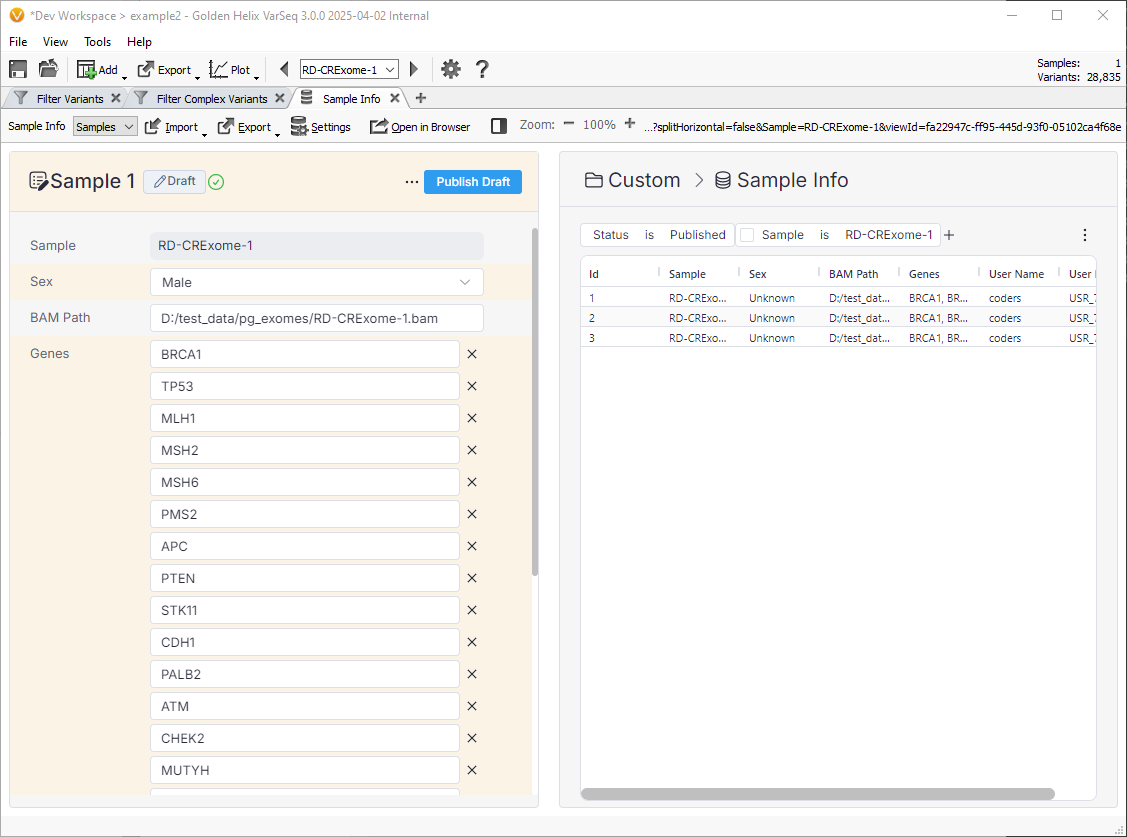
This allows you to edit the fields in the catalog by hand. In this example, we can add Genes and adjust the sample BAM bath and Sex fields.
Another quicker way to add sample fields to the catalog is through the bulk upload feature of the Catalogs view. This allows for the easy export of sample fields to a catalog. One of many potential use cases for this would be to create a catalog for storing the results of the Sample Statistics algorithm. This algorithm provides some basic quality control metrics that may be important to save in order to document that the sample passes the QC thresholds.
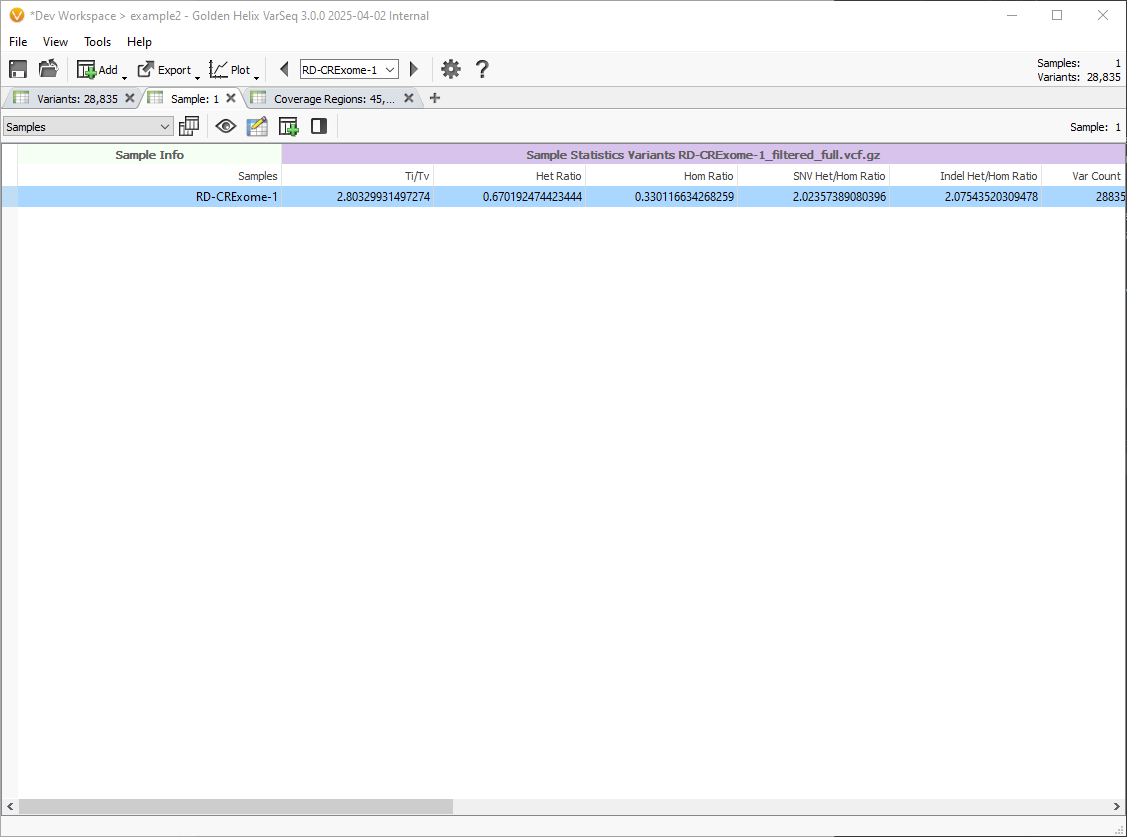
If we create a catalog with these fields, we can then export the data from the VarSeq table into the catalog:
Similar to adding sample fields on import, this process can also be automated as part of a VSPipeline script by creating a saved export that maps the fields in the VarSeq table to the fields in the catalog. This means that these sample quality control fields are reviewed and searched whenever the pipeline runs, and then reviewed and searched at any time in the future.
Conclusion
We hope you enjoyed this brief introduction to some of the exciting new features coming to the VarSeq 3 samples table with VSWarehouse 3. Having easily accessible sample information is crucial for validation and retrospective analysis, forming the foundation for a streamlined analysis pipeline. The catalog functionality represents an advancement in how sample data is managed. If you are interested in exploring how it can be used to streamline your secondary and tertiary analysis, please contact us at [email protected] to learn more.



