In the search for disease causing mutations it is important to determine if the variant has been previously observed in humans and at what frequency. With the advent of increasing genomic information, there is now a variety of different databases and annotation sources that can be utilized. For some, this could be a tedious task that leads only to implementing a few of the more common frequency catalogs, such as dbSNP, gnomAD or ExAC. But what happens if the variant is present in a different database? Well that is where Kaviar comes in, and no this is not for the food connoisseurs.
Kaviar (Known VARiants)
Kaviar is a compilation of SNVs, indels, and complete variants observed in humans that is designed to facilitate testing for the novelty and frequency of variants. More importantly, Kaviar contains 162 million SNPs, including 25 million not observed in dbSNP, 50 million short indels and substitutions, and encompasses 13,000+ whole genomes and 64,000+ whole exomes. The 35 projects and databases that contribute to the curation of Kaviar can be seen in Figure 1. Although not broken down into percentages, 1000 Genomes, dbSNP v146, and 69 Genome Set are three of the largest contributors to Kaviar.

Figure 1: 35 projects and databases are integrated into the Kaviar database
In Varseq, Kaviar has been incorporated into the public annotations and is available for both GRCh37 and GRCh38. When annotated against your variant set, this database will display the dbSNP rsID if available and the Alternate Allele Frequency based on Allele and Alternate Allele Counts, Figure 2.
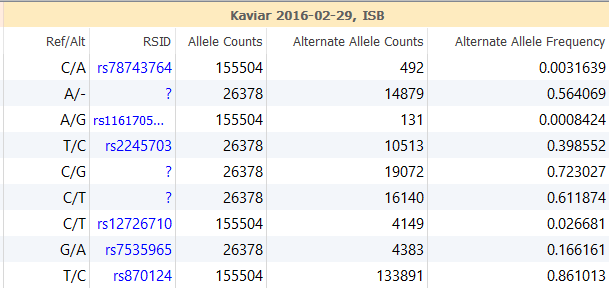
Figure 2: Kaviar can be used in VarSeq to annotate variants and will display the rsID and Alt Allele Frequency
Allele Frequency Aggregator (ALFA), dbGAP
The database of Genotype and Phenotypes (dbGAP) is created by NCBI and contains the results of over 1,200 studies that have investigated the interaction of genotype and phenotype. This database has over 2 million subjects and hundreds of millions of variants along with thousands of phenotypes and molecular assay data. However, the data generated from these studies, also known as Genomic Summary Results (GSR), was limited to controlled access. Meaning that researchers need to apply for permission with dbGAP to gain access to projects. As of recently, however, NCBI has lifted the restriction to GSR making more genetic information publicly available. Furthermore, to promote research toward identifying genetic variants that contribute to health and disease, NCBI developed the Allele Frequency Aggregator (ALFA), which computes allele frequency for variants in dbGAP across approved un-restricted studies. This database is curated and available in VarSeq, Figure 3.
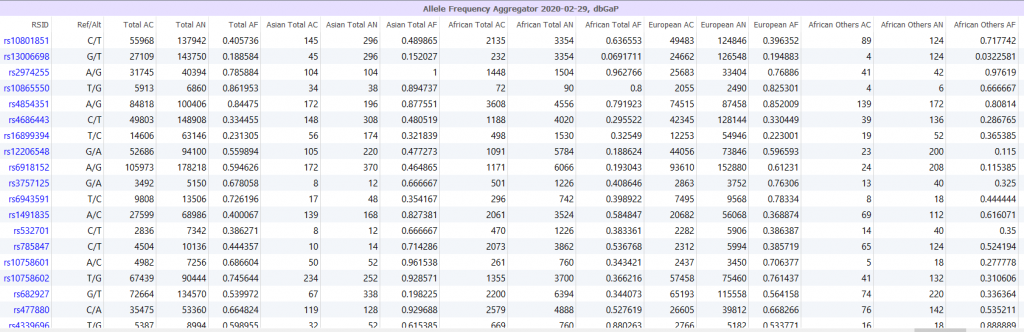
Figure 3: Allele Frequency Aggregator, dbGAP is available as a public annotation in VarSeq
ALFA can be used as an allele frequency database, which contains over 1 million dbGAP subjects, which can help facilitate discoveries and interpretations of common and rare variants with biological impacts or causing disease. This initial release contains frequency for 447 million variants including 4 million novel ones aggregated from 551 billion genotypes. Furthermore, as shown in Figure 3, this data comprises subjects from 12 diverse populations including European, African, Asian, Latin American, and others.
In summary, we are happy to comment on the curation of these databases into VarSeq. Both Kaviar and ALFA are some of the most comprehensive collection of human genomic variants currently available to the public and to our users. We hope that these annotations will alleviate the complexities of utilizing different frequency databases and further your identification of disease-causing mutations.
As always, if you have any questions regarding the content in this blog post or questions about our software, please do not hesitate to reach out to [email protected]. Additionally, if you would like to request a free trial to our software, please visit our website to apply.



