Earlier this year we completed the marriage of SVS and GenomeBrowse. When we released Version 8 of SVS we completed a major engineering task. A lot of things under the hood of both products had been changed to create a seamless experience for our users. The new and improved SVS platform is based on a technology stack that allows us to accelerate method development and even helps us to launch new product faster. More about the latter in another blog post.
Now, the new SVS 8.2 comes with a number of new methods and features:
MM-KBAC
MM-KBAC, or Mixed Model Kernel Based Adaptive Clustering combines the KBAC method developed by Lui and Leal (2010) with a random effects matrix to adjust for relationships between samples. This method is designed to correct for batch effects, cryptic relatedness and known structure from large pedigrees in large-N DNA sequencing studies. The KBAC algorithm takes a binary dependent variable and uses transformations to convert the logistic regression model to a linear model so that EMMAX (Efficient Mixed Model Association eXpedited) can be used to solve the equations. Please take a look at Greta Linse Peterson’s recent blog post for more information on MM-KBAC.
On a related note, we are also very excited that we have been accepted to present this method at ASHG this October – visit us in booth #422!
gBLUP
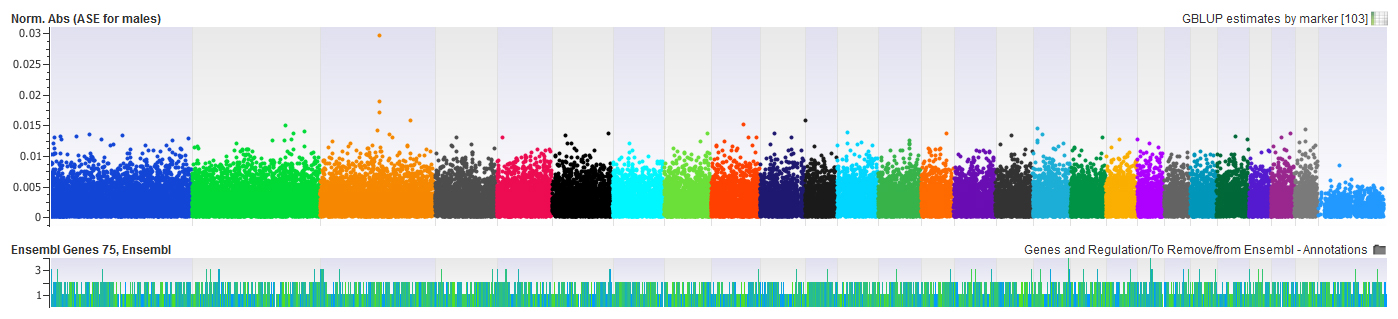
Genomic best linear unbiased prediction (gBLUP) is a method that uses relationships between samples to predict the genetic merit of a sample or the allele substitution effects of a loci. For this purpose, either a genomic relationship matrix or a pedigree based relationship matrix is used. The genomic relationship matrix computes the covariance between samples based on observed genomic similarity, rather than on expected similarity based on pedigree structure. Consequently, more accurate predictions of merit can be made when the samples cannot be completely described by a pedigree due to missing information or complex pedigree structures. gBLUP has been used for the prediction of merit in livestock and plant breeding, but has the potential for wider use. For example gBLUP has some abilities to forecast disease risk, and can also prove useful in estimating variance components and genomic heritability.
Runs of Homozygosity
“Runs of homozygosity” or ROH are regions of the genome where both alleles in a genotype are the same. This can be due to having identical regions of the chromosomes inherited from both parents. Another cause can be due to copy number loss or a missing portion of a chromosome from one parent. Either of these cases creates a run of homozygous variants, while an ROH can be short, in general we would expect an ROH to be longer than 500,000 base pairs (nucleotide letters) long.

Researchers are interested in studying the presence of ROH or the association with diseases for various reasons. An ROH can exist because of inheriting the region from both parents who share a common ancestor, including children resulting from consanguineous marriages. Thus the distribution of ROH among samples can be used to study gene flow and population genetics, however, the analysis of common ROH among samples can be important medically. Association between ROH and a disease phenotype can detect potentially causative recessive variants and haplotypes (a variant or run of variants inherited from both parents). There are numerous examples of recessive diseases, but one recent published paper found evidence that an ROH is associated with Alzheimer disease (Ghani 2013). In SVS 8.2 we refined the computation of ROH giving our users better and more control over the definition of a run to access to this information.
Support of Mitochondrial Research and Clinical Testing
 With the advances in genetics and molecular biology, our users are increasingly focusing on understanding the complexity of mitochondrial disorders. According to the United Mitochondrial Disease Foundation about 1,000 to 4,000 babies are born with a mitochondrial disorder each year, for comparison according to the Centers for Disease Control (CDC) about 2,500 babies are born with Cystic Fibrosis each year. We were able to update our default gene track and assembly to provide the most widely accepted mitochondrial reference sequence and gene annotations to support workflows for mitochondrial research and clinical testing.
With the advances in genetics and molecular biology, our users are increasingly focusing on understanding the complexity of mitochondrial disorders. According to the United Mitochondrial Disease Foundation about 1,000 to 4,000 babies are born with a mitochondrial disorder each year, for comparison according to the Centers for Disease Control (CDC) about 2,500 babies are born with Cystic Fibrosis each year. We were able to update our default gene track and assembly to provide the most widely accepted mitochondrial reference sequence and gene annotations to support workflows for mitochondrial research and clinical testing.
Various New Features
- Compute a numeric “A” kinship matrix: This allows our users to take advantage of pedigree information that has been collected as part of a study. It builds a kinship matrix based on the degree of relatedness from the pedigree. This feature can be used instead of the inferred kinship matrix, computed from genetic data, that SVS has been supporting for some time already and can be used with GBLUP and other mixed model algorithms.
- Fst Confidence Intervals: Fst is a measure of population drift. It is computed by comparing the allelic sharing between pairs of sub-populations. SVS provided the ability to obtain the Fst value already. Now, we added confidence intervals leveraging bootstrapping algorithms.
- Ability to select the allosome for gender inference: This will allow non-human researchers to pick the chromosome that is best to use for gender inference (i.e. Z for Chickens).
More information about these new features can be obtained from the SVS Manual and details on the release can be found in the SVS 8.2 release notes.
We value your input
SVS adoption by the research community and the translational genomics community is driven by the input we receive from our users and experts in the field. I’d like to invite you to share your thoughts on the future direction of SVS with us. Please feel free to send an email to [email protected].
What to expect from SVS in upcoming releases
Based on our user feedback so far, we will continue to add new methods for Large-N DNA-sequencing studies in the near future, including SKAT-O, a gene/transcript collapsing method that tests for the association between rare variants and a continuous or binary phenotype using kernel machine methods. Just like our existing gene and transcript based collapsing algorithms, it can also adjust for covariates.
We will also continue expanding the methods we offer for genomic prediction by adding Bayes-C and Bayes-Cpi (Zeng 2012). This will assist our agrigenomic customers as they predict genomic breeding values and train/validate the effect that genetic markers have on the production/yield traits for their animals or plants.
Dear Steve:
Thanks for your quick reminder.
I am interested in getting my genome sequenced and analyzed, and am looking for the best way to do that.
I am a retired (from Rutgers) molecular biologist as you will see if you check out my website below.
Getting the sequence these days is, I know, relatively straightforward; analyzing it is not.
It appears from your email that you might be able to help me, and if true, I would be grateful.
The reason is that I suspect I am in very early stage dementia and would be interested in analyzing genes
expressed in my brain to see if I can identify a possible causative mutation. Needle in a haystack eh?
If you, or a person/organization you can recommend, would be interested I would appreciate your advice.
With best wishes – Dave
David T. Denhardt, PhD, FRS(C)
Emeritus Professor of Cell and Molecular Biology
Division of Life Sciences, Rutgers University
http://lifesci.dls.rutgers.edu/~denhardt/