For the SVS 8.2 release we decided to improve upon the existing ROH feature. The improvements include new parameters to define a run and a new clustering algorithm to aide in finding more stringent clusters of runs. The improvements were motivated by customer comments and a recent research paper by Zhang 2013, “cgaTOH: Extended Approach for Identifying Tracts of Homozygosity,” that outlined a new approach to identify clusters of runs.
You will also notice that there are now two Runs of Homozygosity menu items. Under the DNA-Seq menu there will be Runs of Homozygosity for NGS and under the Genotype menu there will be Runs of Homozygosity for GWAS. The NGS option now allows for treating missing genotypes as homozygous reference calls and when searching for runs, it does not take into account the gap between variants or the variant density. The GWAS option allows for the user to specify the maximum gap between variants and the minimum density. (This is the same as the old ROH feature.)
New options to create a run:
- Maximum number of consecutive heterozygotes and missing genotypes
- Maximum number of heterozygotes and missing genotypes that can appear in a specified window, in number of SNPs
- In the NGS dialog, treat missing genotypes as homozygous reference calls
New options to define clusters of runs:
These options improve upon the existing clustering algorithm
- Optimal: group runs with similar lengths and start and end positions.
- Haplotype Similarity: group runs with similar lengths, start and end positions, and by allelic matching.
Cluster Segments:
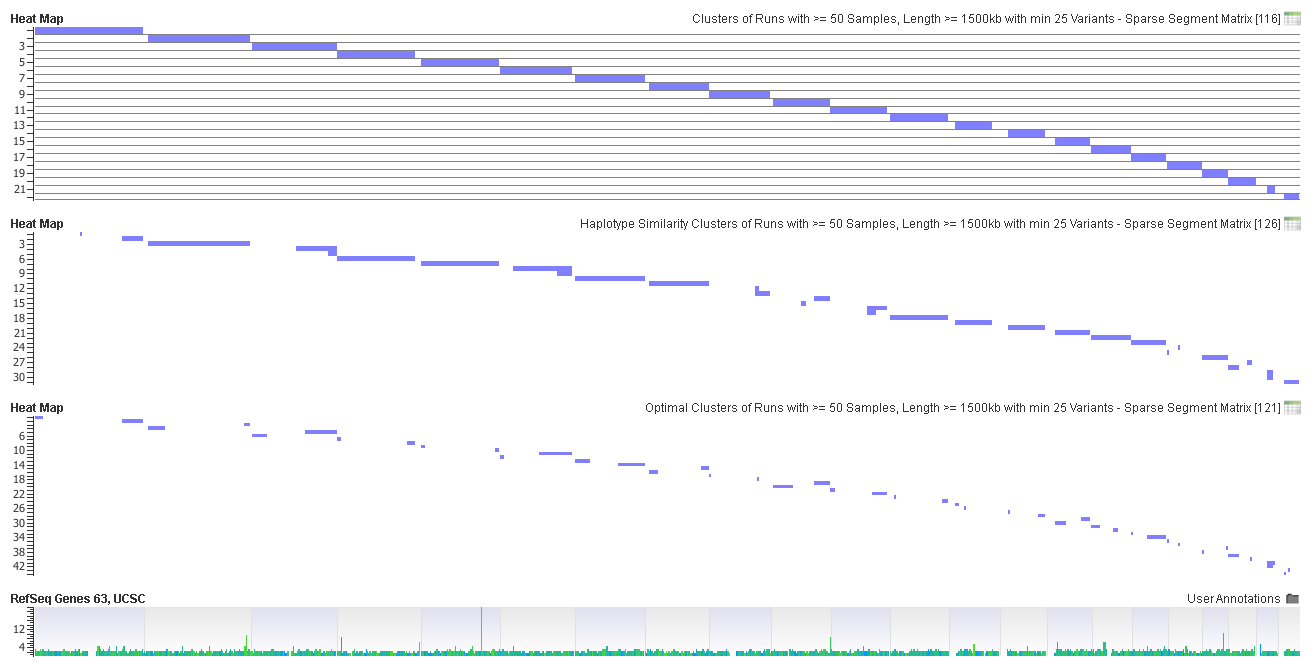 CNAM Output Analysis > Create Sparse Segment Matrix on the cluster of runs spreadsheets.” width=”640″ height=”325″> These were taken by creating a heat map from the results generated by running Numeric > CNAM Output Analysis > Create Sparse Segment Matrix on the cluster of runs spreadsheets.
CNAM Output Analysis > Create Sparse Segment Matrix on the cluster of runs spreadsheets.” width=”640″ height=”325″> These were taken by creating a heat map from the results generated by running Numeric > CNAM Output Analysis > Create Sparse Segment Matrix on the cluster of runs spreadsheets.Looking at the segments, we can see that the optimal and haplotype similarity clusters run over shorter intervals. It should be noted that the intervals that are overlapping are actually clusters whose runs were split into two clusters. The significance on these results can be seen in the run sums output.
The clustering algorithm was developed in the 2013 paper, “cgaTOH: Extended Approach for Identifying Tracts of Homozygosity.” The approach uses a modified repeated binary spectral clustering technique to find local optimal clusters. We first gather clusters of runs by finding intervals where at least a specified number of samples have a run that overlaps this interval. Then those runs are further grouped to find more stringent cluster boundaries. The clustering algorithm uses the Hartigan-Wong k-means algorithm to assign runs to groups. More information about the new clustering algorithm can be found in SVS documentation and the Zhang 2013 paper.
Run Sums Example:
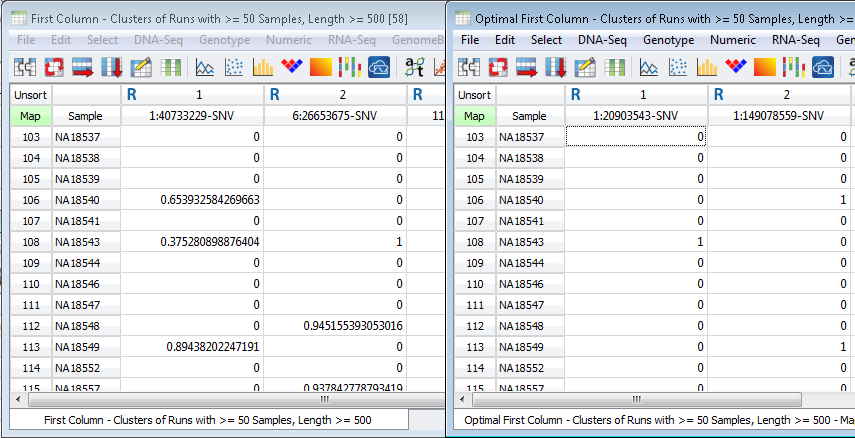
The first column of the spreadsheet on the left is the cluster found using the original clustering algorithm and the first two columns of the spreadsheet on the right are the optimal clusters, the original one was split into two new clusters. Because the runs were grouped more appropriately we see an increase in the run sums, which could lead to lower p-values in association studies. Reference the Zhang 2013 paper for examples studies that use this technique.



