Clinical Assessment Tracks
Golden Helix provides a large catalog of annotation sources for our research and clinical clientele. Making these public data repositories available to all our users is no easy task. As Cody Sarrazin mentioned in his blog post, annotation curation is a complex data science pipeline. This process aggregates data from many disparate sources and normalizes it into one harmonious library so users can quickly annotate their genomic datasets. With the final product, you have all genomic data from all these disparate sources for no additional cost. Our efforts in data curation save you all the hard work of having to do it yourself. We have licensed users who don’t even access our software but instead just want access to our curated annotations! Now, how’s that for a testament to the quality of our data curation?! In this blog series, I will provide detailed information on various annotations, including frequency tracks like ExAC/gnomAD, functional prediction databases, and transcript annotations — all key inputs to robust variant annotation and interpretation workflows. I’ll start with annotations that can aid users in making clinical assessments.
Clinical Assessment Annotations
As I mentioned, Golden Helix provides a variety of annotations from a variety of sources. Whether you want to assess the impact on a specific transcript in a gene track (i.e. RefSeq, Ensemble, etc.), or want to use dbNSFP to predict functional impact of any variant. The VarSeq clinical platform is built on a strong foundation of data curation and annotation algorithms to ensure the variants identified have all the information required to make the correct clinical assessments. A good example track is ClinVar, which houses data fields ideal for finding information pertaining to existing clinical variant assessments. This public archive from NCBI is built by the collaborative submissions of many clinical labs (both commercial and academic) reporting the relationship among human variants and phenotypes with supporting evidence from dbSNP. ClinVar processes submissions reporting variants found in patient samples, assertions made regarding their clinical significance, information about the submitter, and other supporting data. Structured variant classification workflows, such as those based on ACMG/AMP guidelines, rely heavily on ClinVar evidence to support pathogenicity assertions. The alleles are mapped to reference sequences and reported according to HGVS standards. There is an abundance of fields contained in ClinVar and VarSeq provides many ways to view these fields (Figures 1, 2,& 3).

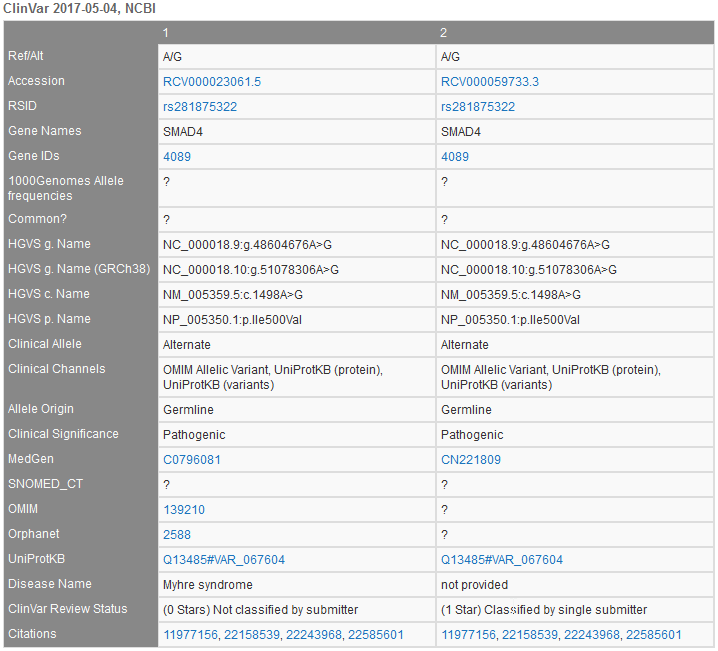
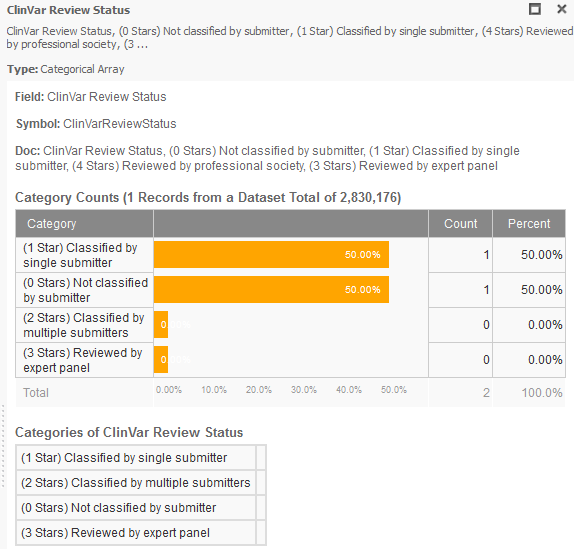
ClinVar is an active partner of the ClinGen project, which provides data for evaluating and archiving the results of clinical assessments by recognized expert panels and providers of practice guidelines. Experts will review the evidence to assign appropriate levels of confidence to the assertions made regarding these alleles. It is important to note that users of ClinVar can examine the level of review of these submissions, in this a four-star rating system as shown in VarSeq as the “Review Status” (Figure 4).
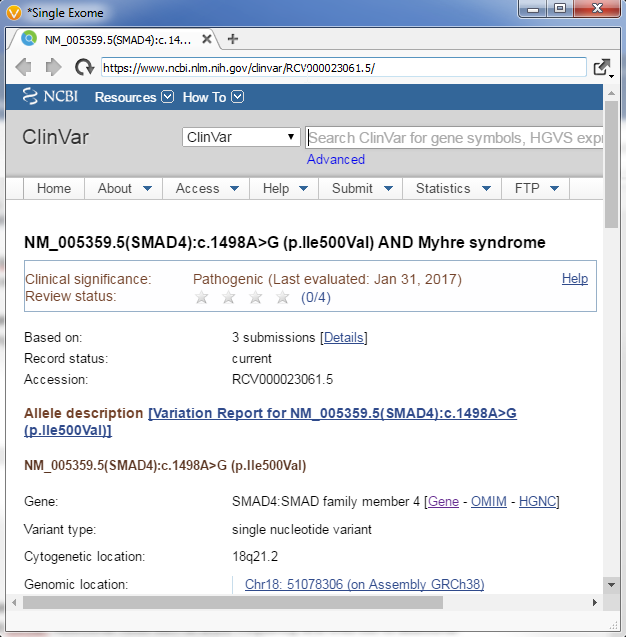
Another useful tool in ClinVar and other annotations are the url links for specific fields. ClinVar has hyperlinks out to NCBI (Figure 5), OMIM, Orphanet, and UniProtKB.
These are just a few examples of the many useful fields available in ClinVar that can assist in your annotation and interpretation process. Another application of VarSeq’s annotations is to filter variants based on any of the fields contained in any database. In a previous blog post, Steve Hystad provides insight on how to perform some custom variant filtering with fields from ClinVar. ClinVar isn’t the only clinical assessment database available, users can also gain access to OMIM as well.
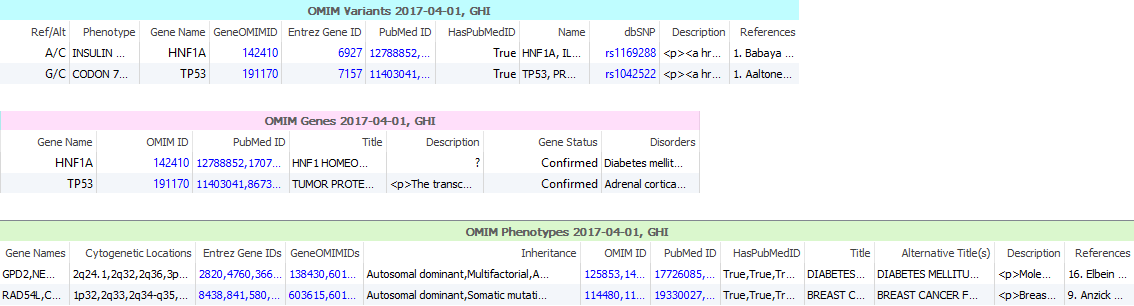
OMIM is a comprehensive, authoritative compendium of human genes and genetic phenotypes. It is authored and edited at the Johns Hopkins University School of Medicine and is freely available with almost daily updates. Its contents are based on selection and review of published biomedical literature and is designed for use primarily by physicians and researchers with a numbering system widely used in the medical literature as an index for genetic diseases. OMIM contains information on all known Mendelian disorders and over 15,000 genes. It focuses on the relationship between phenotype and genotype and contains links to associated publications.
With the careful curation of the OMIM resource at the Phenotype, Gene and Variant level (Figures 6 & 7), OMIM annotations contain:
- Functional description of genes and phenotypes
- Lists of phenotypes linked to genes with supporting evidence and modes of inheritance of the phenotype (autosomal dominant, etc.)
- Paper references with relevant PubMed and direct URLs
- Links to clinical relevant genetic resources such as testing guidelines, ontology and gene test registries
- Descriptive interpretations for variants curated from published papers with family and disease context

At Golden Helix, we strive to not only provide our users with the best form of curated databases giving convenience and power to our users making clinical assessments but to maintain this quality for all of our annotations — supporting the full breadth of clinical genomics workflows in both research and diagnostic laboratory settings. Not only are we representing this data in our table view, but also giving the user capability to create filters for important fields, such as pathogenicity. Stay tuned for the next post in the series describing various allele frequency annotations available in VarSeq.




Thanks for sharing this wonderful article. Its very interesting to read and informative too. Best wishes