We had a wonderful turnout for our recent webcast, “Reduce Turn-Around with Enhanced Cancer Annotations & Golden Helix CancerKB Updates.” Thanks so much to those who were able to join us! And not to worry, we have a link to the recording here just in case you weren’t able to make it. We covered the gamut of new and updated annotation tracks available in VarSeq along with the wealth of info provided by our new Golden Helix CancerKB database – all intended to transparently streamline your assessment process.
As Next-Gen Sequencing continues to push the boundaries of cancer treatment, oncology will become individualized with treatment strategies that are tailored to an individual and their specific cancer. The ever-increasing number of biomarkers correlated to targeted therapies is meaningless without comprehensive genetic profiles that include actionable variants that often go overlooked by gene panels simply because they weren’t one of a few targets. Now with the same amount of tissue samples you can get the comprehensive picture you need for targeted treatments – matching patients to approved therapies and clinical trials – truly make oncology an individualized medicine that can radically improve patient outcomes.
While comprehensive genomic profiling will undoubtedly play a major role in the future of medicine, its evolution is a dynamic and iterative progression. Our very understanding of the disease is constantly expanding driven by revolutionary techniques and approaches that seek to improve upon themselves, challenges to be overcome. At Golden Helix, those challenges are our bread and butter. A few we’re focused on are: 1) accurately identifying biomarkers; 2) creating reproducible clinical evaluation workflows; and 3) efficiently wrangling the numerous moving pieces needed to render an evaluation within a cross-functioning team.

We’ve worked hard to develop solutions for each of these: developing sensitive algorithms for variant and biomarker ID, automating oncogenicity scoring that’s actually reproducible according to ACMG/AMP guidelines; and leveraging and integrating numerous annotations and expert-curated databases into one spot synthesizing every piece of relevant information into a clinical context that can even leverage phenotype and keep track of your entire teams’ status. Of these solutions, we want to specifically focus on updates to those annotation sources and a new database that distills a plethora of information into what is clinically relevant.
Updated Cancer Annotations
Of the numerous annotation sources we provide, we’re excited to announce upcoming COSMIC updates. Currently, COSMIC 92 is available in VarSeq, but the release of COSMIC 94 at the end of next month adds a whopping 350,957 new features. As a preview of what to expect with the COSMIC 94 update, the overall focus was on curation updates for rare lung and pancreatic cancers, as well as 12 genes known to be involved in apoptosis pathways such as BLM, CHEK2 , and, FLT4. Updates to the cancer hallmarks annotation included 9 Cancer Gene Census Tier 1 genes causally associated with cancer including GATA1, COL2A1, CEBPA, and CDKN2C. The function information included provides an improved understanding of how these genes contribute to tumor development.
Available in VarSeq are updates to our Cancer Ontologies. These updates reflect the push by the WHO and others in recent years to characterize hematological cancers. Prompted by these efforts we have updated the list of available cancer ontologies to ensure tumor type-specific interpretations are recorded. We curate these cancer ontologies using the NCI Thesaurus and OncoTree, an open-source ontology that was developed at Memorial Sloan Kettering Cancer Center (MSK) aimed at standardizing cancer type diagnosis from a clinical perspective.
Another update can be found for a very popular feature of our VSClinical cancer workflow. The access provided to NCI clinical trial information will now be updated monthly, ensuring that you are always seeing the most up-to-date information on recruiting or active trials and their proximity to your patients.
We are excited to feature these annotation updates, but one we’re particularly excited about is the Golden Helix CancerKB database. Our very own Genomic Curator and Product Quality Scientist, Julia Love, has been working closely with the team of expert curators to develop this game-changing resource.
Golden Helix’s CancerKB Database
In case it’s new to you, Golden Helix CancerKB is a Golden Helix curated collection of interpretations at Gene and biomarker levels, including clinical interpretations for drug sensitivity and resistance, and prognostic and diagnostic interpretations for a variety of different tumor types. You can see in the figure below the automatic interpretation provided for an ABL1 fusion with BCR.
Figure 3: An automatic interpretation provided for an ABL1 fusion with BCR by Golden Helix CancerKB
The database is curated by expert curators that have years of experience writing clinical somatic variant interpretations. They gather information from numerous sources including the National Comprehensive Cancer Network, cBioPortal, variant interpretation for cancer consortium, and many others finding the most current information they need to describe a gene’s function, impact, and alteration frequency in the context of different cancer types. The most prominent biomarkers in these genes are also well described in terms of their role in cancer, how common the mutation is for a given tumor type, and if the biomarker has any diagnostic or prognostic implications. Drug sensitivity or resistance information for the biomarkers is also investigated from a therapeutic context and incorporated into interpretations. The real value of Golden Helix CancerKB is not only having access to these comprehensive expert-curated interpretations but having these interpretations automatically fill into VSClinical and clinical reports. With most of the work done for you, you can spend less time scouring the internet, gathering the latest information, and writing up interpretations from scratch.
In the latest version of Golden Helix CancerKB, we prioritized including genes and biomarkers with tier level I drug/prognostic/diagnostic evidence including over 100 new interpretations for genes and biomarkers with tier l level clinical evidence. In addition, ~180 existing Golden Helix CancerKB genes and biomarker interpretations with tier level I evidence have been updated to include the latest information. These updates will be occurring more and more frequently as we level up our release turn-around time. As usual, you can opt into sharing your written interpretations with us directly informing us on the field’s most current focuses and most utilized databases. With numerous interpretations submitted for review by our expert curators, your submission will inform them on what to prioritize and ultimately how tailored Golden Helix CancerKB will be to your field.
ClingGen Expert Curated Interpretations Database
The ClinGen Expert Curated interpretations database is updated routinely and has always been available for use as an annotation source for VarSeq projects. However, there’s more to this source than you might realize. By incorporating it into your VarSeq projects and workflows, if you haven’t already, you’re including ACMG criteria recommendations, interpretations, and comments from several ClinGen Expert Panels. There are over 80 established panels ranging from cardiovascular, hearing loss, hereditary diseases, somatic cancers, and more. These panels are composed of teams of experts in different clinical domains focused on evaluating the clinical validity of gene-disease relationships and pathogenicity of individual genetic variants. They evaluate evidence to classify a variant on a spectrum from pathogenic to benign with respect to a particular disease and inheritance pattern. The comments that are included for each criteria describe not only the reasoning behind why a given ACMG criteria was scored but also include comments for the unmet criteria. Each expert panel has published papers describing the ACMG scoring logic as it pertains to different genes and diseases in detail.
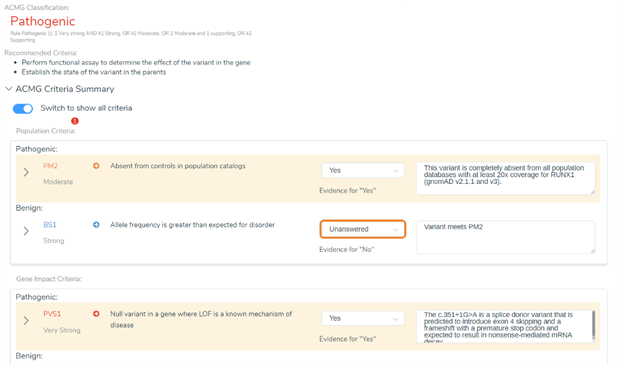
In the next VarSeq release, we are taking all the valuable variant classification information from this database to the next level. Instead of just using this source as an annotation in your projects, you can now automatically score variants and have the interpretations and criteria comments automatically applied using VSClinical. You can see an example of this in the figure below showing a RUNX1 variant and the comments automatically provided regarding the recommendation of PM2 and PVS1. We discuss additional information these interpretations provided in the webinar and specifically how they impacted our criteria.
Another feature that is being integrated into VSClinical is related to one of the ClinGen Expert Panels in particular – the TP53 panel.
ACMG TP53 rule specifications
The IARC (International Agency for Research on Cancer) is a part of the world health organization, has complied various data and information on human TP53 gene variations as they relate to cancer. This database is a compilation of TP53 mutation data for somatic and germline cancers along with functional assessments collected since 1989 providing useful information for tumor-specific mutations patterns in addition to capturing patient-specific information. So how does having access to this information change TP53 variant classification with the ACGM guidelines? Ultimately many TP53 variants were classified as variants of uncertain significance by the original guidelines but by incorporating the phenotypic and functional data from the IARC TP53 database, the impact of TP53 variants became better understood. In December 2020 the ClinGen TP53 Expert Panel with other researchers and institutions published the new ACMG TP53 rule specifications. A number of ACMG criteria have been adjusted for TP53 such as lower allele frequency cut-offs for BA1 and BS1, and adjusted point system for PS2 and PM6 regarding de novo variants to name a few, and several criteria are excluded from classifying TP53 such as PM3, PM4, PP2, PP4, and PP5.
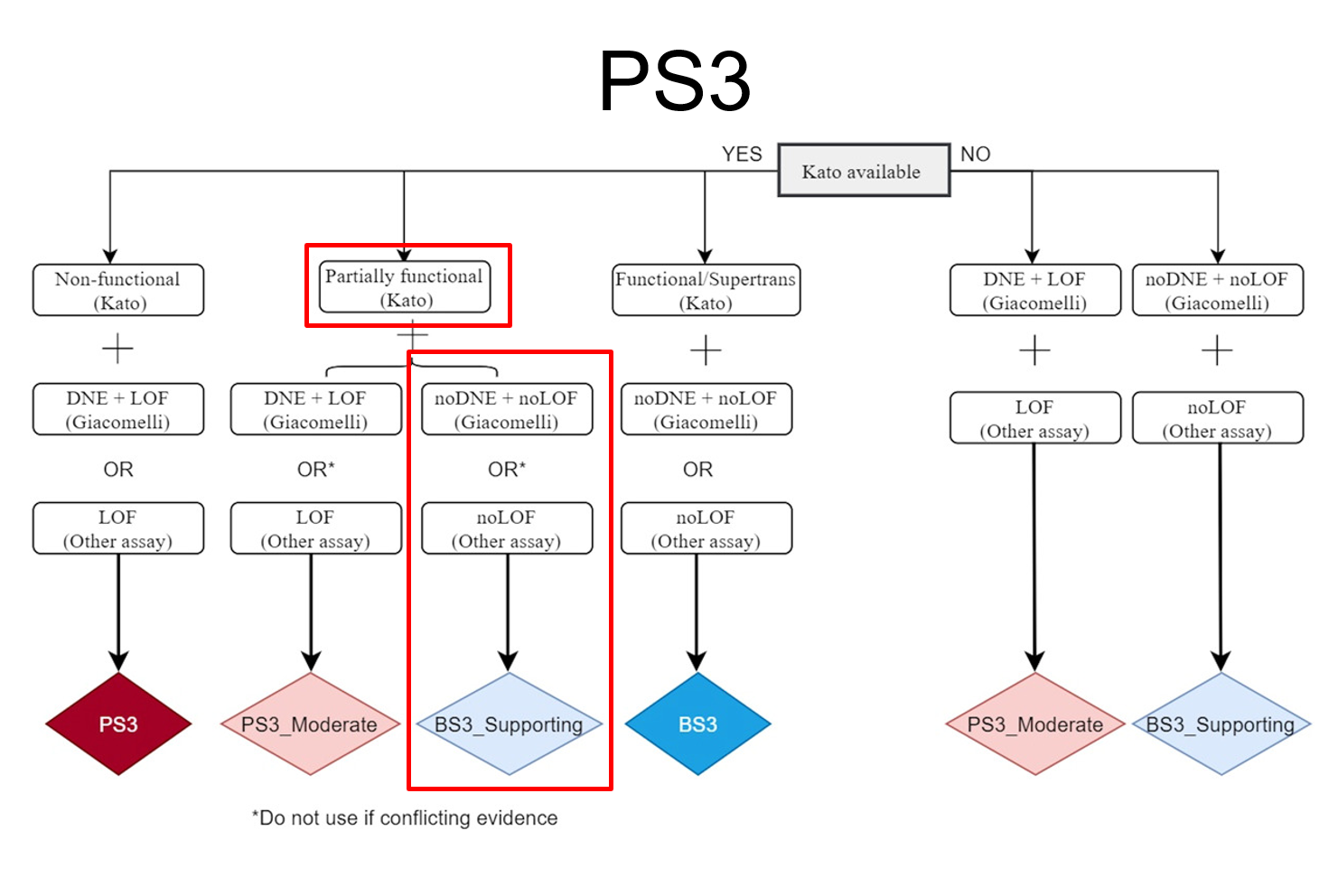
The figure below shows an example of how the criteria have been modified for TP53 variants by including functional data into the scoring. This decision tree combines the work published by Kato et al (2003) and Giacomelli et al (2018) which affected the application of PS3 and BS3 for variant classification. At the top of the tree, the first decision relates to the availability of functional data based on transactivation activity for a variant according to Kato et al (2018). Next, transactivation activity is used to determine whether the mutant TP53 protein is functional, non-functional, or partially functional. Last, the dominant-negative effect (DNE) and Loss of function (LOF) were measured by the Giacomelli group and other assays. These thresholds determine the impairment of non-mutant wild-type TP53. Clearly, assessing each TP53 variant with this decision tree could be quite labor-intensive – but there’s good news. This decision tree and application of many of these new TP53 rule specifications can now be automated with VSClinical creating an auto classifier specific to TP53 and dramatically simplifying the classification process.
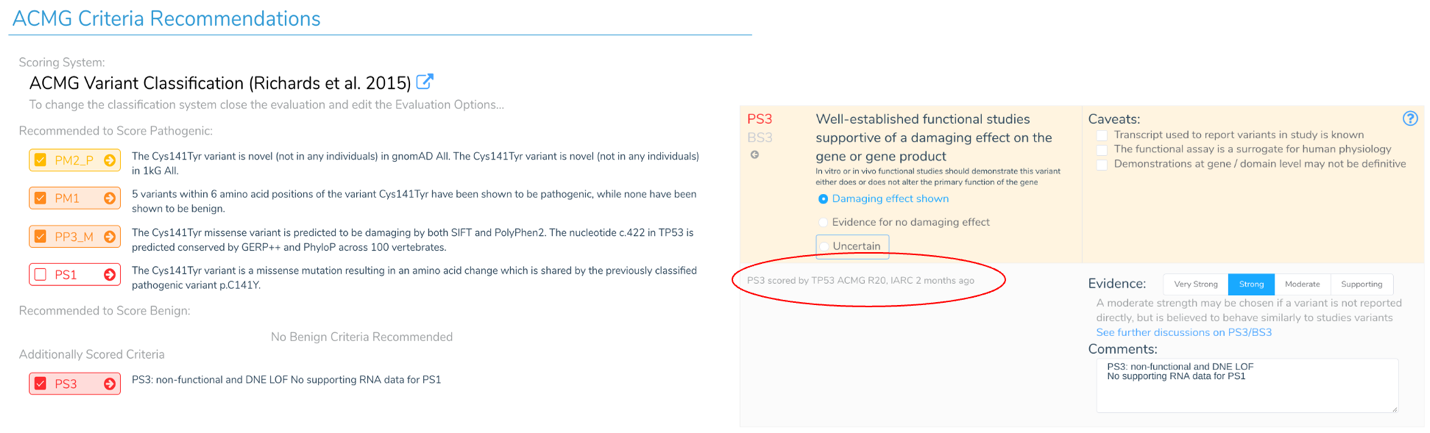
The availability of this TP53 specific criteria allows us to apply the correct criteria for these notoriously difficult-to-score variants. The figure below shows an example of recommended criteria for a TP53 variant according to the TP53 expert panel. We walk through scoring this variant in the webinar, but you can see PS3 is recommended instead of PS1 reflecting unique considerations for TP53 variants. In this instance, PS1 only applies if there is supporting RNA data – something this specific variant lacks. We click on the PS3 criteria we can see details, including that the TP53 expert panel applied PS3 to this variant 2 months ago. Without this specific and up-to-date annotation track, one could easily and incorrectly apply PS1.
I hope this discussion gave you a sense of how these new and updated annotations and databases can impact your assessments. The information they provide not only helps keep you current with scoring criteria changes, but automatic recommendations and comments do the heavy lifting, radically reducing the amount of time you must commit to the evaluation process – time that’s better spent elsewhere.
References:
Fortuno C, Lee K, Olivier M, Pesaran T, Mai PL, de Andrade KC, Attardi LD, Crowley S, Evans DG, Feng BJ, Foreman AKM, Frone MN, Huether R, James PA, McGoldrick K, Mester J, Seifert BA, Slavin TP, Witkowski L, Zhang L, Plon SE, Spurdle AB, Savage SA. (2021). ClinGen TP53 Variant Curation Expert Panel. Specifications of the ACMG/AMP variant interpretation guidelines for germline TP53 variants. Hum Mutat. 42(3):223-236. doi: 10.1002/humu.24152. PMID: 33300245.
Giacomelli AO, Yang X, Lintner RE, McFarland JM, Duby M, Kim J, Howard TP, Takeda DY, Ly SH, Kim E, Gannon HS, Hurhula B, Sharpe T, Goodale A, Fritchman B, Steelman S, Vazquez F, Tsherniak A, Aguirre AJ, Doench JG, Piccioni F, Roberts CWM, Meyerson M, Getz G, Johannessen CM, Root DE, Hahn WC. (2018). Mutational processes shape the landscape of TP53 mutations in human cancer. Nat Genet. 50(10):1381-1387. doi: 10.1038/s41588-018-0204-y. PMID: 30224644
Kato S, Han SY, Liu W, Otsuka K, Shibata H, Kanamaru R, & Ishioka C. (2003). Understanding the function-structure and function-mutation relationships of p53 tumor suppressor protein by high-resolution missense mutation analysis. Proc Natl Acad Sci U S A, 100(14): 8424–8429. doi:10.1073/pnas.1431692100



